Project 1: Ansible
Deze repo bevat de opgave voor een project volgend op de workshop van Ansible.
Doelstelling
In dit project:
- toon je aan dat je verschillende systeembeheertaken kan uitvoeren met Ansible
- Pas je zo veel mogelijk de
best practicestoe om Ansible-taken uit te voeren.
Project - Opgave
Stap 1 - Deploy instantie / Voorbereidingen
Voor dit project werk je met een aparte deployment in een "project" op de private cloud van onze opleiding.
Dit zorgt er voor dat je een eigen, geïsoleerde omgeving hebt waarin je vrij kan werken zonder dat dit invloed heeft op andere instanties die je reeds gemaakt hebt.
-
Je progressie en uiteindelijke oplossing komt terecht in een repo met de naam
2526-IaC_Ansible_Project-Familienaam Voornaam -
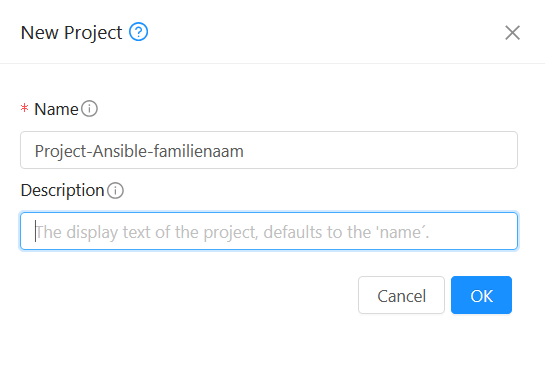
Meld je aan in de CloudStack-portal en maak eerst een nieuw
projectaan met de naamProject-Ansible-familienaam.- Project menu openen
- Nieuw project aanmaken
- Project openen
- Project menu openen
-
Maak vervolgens binnen dit project je VM-instanties aan voor dit project.
- Gebruik voor Computer Offering:
IaC - ikdoeict(bij de router gebruik jeCisco CSR1000v) - Voor de naamgeving van je machines:
Ansible-Control-Host-familienaam,Managed-Host-1-familienaam,Managed-Host-2-familienaam,Managed-Host-3-familienaamenRouter-familienaam(OS: zie tabel hieronder).
- Gebruik voor Computer Offering:
Bekijk onderstaand schema goed. Dit geeft goed weer hoe de verschillende machines in je project met elkaar verbonden zijn en welke rollen ze hebben.:
- Noteer je ip-adressen: De ip-adressen kan je best hieronder noteren.
| Virtual Machine | OS | IP-adres | credentials |
|---|---|---|---|
| Ansible-Control-Host-familienaam | Rocky | student/student | |
| Managed-Host-1-familienaam | Ubuntu | ubuntu/Azerty123 | |
| Managed-Host-2-familienaam | Ubuntu | ubuntu/Azerty123 | |
| Managed-Host-3-familienaam | Rocky | student/student | |
| Router-familienaam | Cisco CRS1000v | cisco/cisco123 |
- Neem na opstart een snapshot van elke VM.
Op die manier kan je in een latere fase makkelijk teruggrijpen naar een
propereversie van je VM.
Neem eventueel tussendoor ook nog eens een snapshot vooraleer ingrijpende aanpassingen door te voeren. Of... door een snapshot terug te zetten kan je ook je playbook meerdere keren toepassen en testen alsof het de eerste keer is.
Opgelet: Cloudstack is voor jullie op die manier geconfigureerd dat er enkel een snapshot kan genomen worden van een machine als deze machine uitgeschakeld is.
- Zorg er voor dat je op een makkelijke manier de Control Host kan gebruiken. Voorzie je connectie met de Control Host via MobaXterm of nog beter, via een
Remote-SSH-connectie bij Visual Studio Code of gelijkaardig.
Stap 2 - Ansible voorbereiding
-
Installeer Ansible op je Control Host
-
Voorzie
Password-less SSH-Authenticationmet alle nodes (host1, host2 en host3) behalve de router (wél met wachtwoord) en de Ansible Control Host (lokale authenticatie). -
Alle Playbooks, Roles, inventories, variabelen, etc... komen terecht in een subfolder van je home-folder "student". Deze subfolder heet
ansible-project.
Stap 3 - Inventory
- Voorzie een inventory met volgende groepen:
@all:
|--@controlhosts:
| |--controlnode1 => Ansible Control Host
|--@dbservers:
| |--host3 => Load Balancer en Database server
|--@loadbalancers:
| |--host3 => Load Balancer en Database server
|--@routers:
| |--CSR1000v => router
|--@ungrouped:
|--@webservers:
| |--webnode1 => host1: webserver
| |--webnode2 => host2: webserver
- Uiteraard worden variabelen (cfr. Best Practices) niet in de inventory opgenomen maar in aparte en beveiligde bestanden.
Idealiter splits je de "gevoelige" data af van de gewone variabelen en worden deze apart geëncrypteerd opgeslagen.
Eventueel kan je nog wachten om je bestanden met gevoelige data te beschermen om op dit moment nog wat makkelijker te kunnen werken. Maar op het einde van je opgave moet dit uiteraard wel in orde gebracht zijn.
- Voorzie eventueel nu reeds je basis-structuur in de folder van je project.
Stap 4 - Uitvoering van enkele standaardrollen
In onderstaand blok worden verschillende verwachtingen geformuleerd.
Het is aan jou om deze zelf op een zo goed mogelijke manier te implementeren rekening houdend met best practices.
We zullen het geheel zo veel mogelijk in rollen proberen uit te voeren zodat je heel gestructureerd je Ansible-taken kan uitvoeren.
Probeer ook waar mogelijk zo efficiënt mogelijk te werken (loops, conditionals,...)
Taak 0 - Playbook
In de volgende taken wordt gevraagd om alles netjes in rollen uit te werken.
Uiteraard moeten deze rollen aangesproken worden door deze op te nemen in een playbook.
- Zorg er, bij het uitvoeren van onderstaande taken voor, dat je een 'playbook' met de naam
playbook_voornaam.ymlmaakt met daarin verschillendeplaysom de rollen toe te passen op de verschillende servers, routers,...
Op die manier kan je telkens ook stap per stap controleren of je playbook en je rollen hun taken correct uitvoeren.
Taak 1 - Common
- Creëer een nieuwe
rolmet de naamcommondie je nodes een software update/upgrade geeft en dus alle pakketten van je OS (zowel Ubuntu als Rocky Linux) op de recentste versie brengt (eventueel ook de package repository updaten!).
De allereerste keer kan het heel lang duren vooraleer je playbook volledig uitgevoerd wordt als er heel veel updates moeten gebeuren. Heb even geduld of voer update eerst eens manueel uit.
- Voorzie in dezelfde rol dat de
firewall actiefis én eenSSH-connecties toelaat.
Herstart indien nodig de firewall om de regels in werking te stellen. Maak gebruik van Handlers.
Taak 2 - Webservers
-
Maak van de webserver-nodes effectief webservers. We gebruiken
Nginxals webserver-service. Voorzie hiervoor ook een nieuwerolwebserver. -
Bij opstarten van de nodes moet de webservice automatisch opgestart worden.
-
Voorzie in diezelfde rol dat de correcte poorten in de firewall openstaan om connecties met de webservers via
httpénhttpstoe te laten.
Tussentijds kan je best controleren of je kan surfen naar de default-pagina van Nginx vooraleer verder te werken en andere rollen uit te werken.
Taak 3 - Database server
node3 zal zowel als Load Balancer fungeren én als Database server.
- Voorzie een nieuwe Ansible-
rolmet de naamdatabasewaarmeemysql-servergeïnstalleerd wordt op node3.
- Zorg dat de service gestart is, ook na een reboot.
- Wellicht zal je een extra python-gerelateerd packet moeten installeren (bekijk goed je foutmeldingen)
-
Voorzie in diezelfde rol dat de firewall connecties met deze databaseserver toelaat als deze afkomstig zijn van de webservers.
Je hoeft dus geen rekening te houden met de poorten. Aan de firewallregels van je database-server voeg je dus de source ip-adressen (publieke netwerk) van je webservers toe aan de zonePublic(ip's op een dynamische manier en dus niet "hard coded"). -
Voeg een nieuwe mysql-gebruiker toe waarmee we later in de mysql-databank kunnen aanmelden. Gebruik als nieuwe user je eigen voornaam en kies een bijhorend wachtwoord dat je, cfr best practices, apart als variabele opslaat.
Idealiter zorg je ervoor dat wachtwoorden niet verschijnen bij het uitvoeren van je play in de output of opgenomen worden in logs.
-
Creëer in je mysql-server een nieuwe databank met de naam
voornaamfamilienaam(aan te passen met je eigen naam uiteraard). -
Voer nu ook via deze rol een
queryuit op je mysql-server:- Je weet dat via een gewone command-line deze query kan uitgevoerd worden met
mysql --user=username --password=xxxx --execute="select ....;". - de query vraagt een lijst van de users uit de tabel
uservan de databasemysql. Neem de veldenuser, host en password_last_changedop in de query. - Registreer de output van deze query in een variabele.
- Toon, bij het uitvoeren van je playbook, het resultaat van dit command (dat in een variabele zit) op het scherm.
- Je weet dat via een gewone command-line deze query kan uitgevoerd worden met
Wil je tussendoor eens testen of je Playbook wel het gewenste resultaat oplevert?
Dan kan je eventueel nu als test eens manueel proberen om een connectie te maken vanaf een webnode naar de mysql databank met de gebruiker die je voorzien hebt.
Om dat te kunnen doen zal je dan wel even de mysql-client manueel moeten installeren op je webnode. Dit pakket werd immers niet opgenomen in de vereiste packages (en moet er ook niet in...).
mysql -h <ip_van_de_db_server> -u <aangemaakte_user> -p
Taak 4 - Loadbalancer
Aangezien we 2 webservers hebben die dezelfde content aanbieden kunnen we daarvoor een loadbalancer plaatsen die requests verdeelt over beide nodes.
-
Voorzie een nieuwe rol
loadbalancerdie de package installeert omNginxte implementeren. -
De configuratie van de loadbalancer moet aangepast worden:
- Maak van dit bestand een template in Ansible waarin je volgende parameters dynamisch maakt (variabelen) die @runtime door Ansible ingevuld worden:
- de poort waarop de loadbalancer luistert
- het ip-adres van de backendservers
- Plaats uiteraard de template en de variabelen op de juiste plaats in je Ansible-project.
- Maak van dit bestand een template in Ansible waarin je volgende parameters dynamisch maakt (variabelen) die @runtime door Ansible ingevuld worden:
-
uitleg over de configuratiefile van nginx kan je makkelijk online vinden (vb https://docs.nginx.com/nginx/admin-guide/load-balancer/http-load-balancer/ of ...)
-
Vermoedelijk zal
SELinuxin de weg zitten om je load balancer requests te laten doorsturen naar upstream nodes. SeLinux is een ingebouwde beveiligingsarchitectuur, die anders dan een firewall nog veel meer de interne processen controleert.
Je zal wellicht de nginx-service, in SELinuxhttpd_tgenaamd, de nodige permissive toegang moeten geven. Dit kan je in deze situatie ook makkelijk met een Ansible-module doen (community.general.selinux_permissive).Alternatieve aanpak (meer gericht, beter practice):
In plaats van de hele nginx-domain permissive te zetten kun je beter een gerichte SELinux boolean gebruiken:- name: Allow nginx to connect to upstreamansible.posix.seboolean:name: httpd_can_network_connectstate: truepersistent: trueDit is veiliger omdat je enkel de specifieke connectie-mogelijkheid aan nginx geeft in plaats van de volledige proces-domain in permissive modus te zetten.
-
De module om nginx permissive rechten te geven in SELinux heeft ook enkele python dependencies. Die zijn in principe al automatisch mee geïnstalleerd als je de vorige stappen geïmplementeerd hebt. Mocht je die vorige stappen overgeslagen hebben, dan zal je alsnog in deze fase ook de package "policycoreutils-python-utils" moeten installeren. Dus sowieso is het niet slecht om in een rol, die eigenlijk volledig onafhankelijk moet kunnen functioneren, de dependencies te installeren. Je weet immers nooit als deze reeds aanwezig zijn of niet.
Op dit moment kan je controleren of je load balancer wel degelijk zijn connecties aanvaardt en doorstuurt naar de achterliggende nodes.
Je kan uiteraard met je browser eens surfen naar het ip-adres van de load balancer. Je zou dan, zoals te verwachten, de standaard pagina's van de nginx-webserver moeten te zien krijgen.
Omdat het moeilijk is om te weten welke van de twee webnodes nu het antwoord geeft, kan je aan de configuratie van je load balancer (nginx.conf) nog een extra regel meegeven:
add_header X-Backend-Server $upstream_addr;
Deze regel zorgt er voor dat er een extra header toegevoegd zal worden in de response met het ip-adres van de webserver die de pagina teruggaf. Op die manier moet je, met wat refreshen, duidelijk zien (via F12 in je browser) dat er gewisseld wordt tussen beide nodes.
Taak 5 - Diverse
-
Maak een nieuwe rol aan met de naam
varia. -
Zorg in deze rol dat de
hosts-file van zowel je webservers (webnode1 en webnode2), je databaseserver (host3) én de Control Host (controlnode1) aangevuld wordt met de nodige regels om de hostnames van de webservers, de loadbalancer en de router te kunnen resolven naar hun ip-adres. Een ping naar "host3" moet dan prima werken vanop elke Linux-VM van je opstelling. -
Zorg er bijkomend voor dat de hostname de naam van de node in de inventory krijgt. Dus i.p.v. de hostnaam die bepaald werd door de virtualisatieomgeving krijgen je machines de naam uit de inventory.
Een gewijzigde hostname is niet altijd meteen zichtbaar op de bash prompt. Controleren kan met het commando hostname.
Taak 6 - Router
Met Ansible kan je heel veel verschillende devices beheren. In deze taak maken we met Ansible connectie met een Cisco IOS Router (CSR1000v).
- Maak een nieuwe rol aan met de naam
routerconfig.- Pas de "hostname" aan naar
routervoornaam, vb. routersven. - Neem een backup van de running-config en sla deze op in een submap
backupin je Ansible-projectfolder. (Zorg ervoor dat deze map "backup" achteraf ook aanwezig is in je repo op Gitlab samen met je volledige Ansible project.
- Pas de "hostname" aan naar
De CSR1000V router die wij in dit labo gebruiken ondersteunt enkel oudere SSH-algoritmes (diffie-hellman-group14-sha1, ssh-rsa). Recente Red Hat-gebaseerde distributies (zoals Rocky Linux) passen daarentegen een strenge security-policy toe waarbij die oude algoritmes standaard geweigerd worden.
We moeten dus aan beide kanten iets aanpassen, en de aanpassingen verschillen afhankelijk van of je manueel via ssh wil verbinden of via Ansible.
Stap 1 - Systeem-brede instelling (altijd nodig)
Op je control host moet je de cryptografische policy verlagen van DEFAULT naar LEGACY zodat de oude algoritmes opnieuw toegelaten worden:
sudo update-crypto-policies --set LEGACY
Stap 2A - Voor een native SSH-verbinding (ssh cisco@<router>)
Voeg een host-specifieke uitzondering toe in ~/.ssh/config (bestand eventueel aanmaken):
Host <ip_van_router>
KexAlgorithms +diffie-hellman-group-exchange-sha1,diffie-hellman-group14-sha1
HostKeyAlgorithms +ssh-rsa
Stap 2B - Voor een Ansible-verbinding
Ansible gebruikt niet de OpenSSH binary van het OS maar een Python SSH-bibliotheek (paramiko of ansible-pylibssh). Daardoor heeft ~/.ssh/config geen effect voor Ansible - die wordt simpelweg niet gelezen.
-
Zorg dat de juiste Python SSH-bibliotheek geïnstalleerd is
Recente versies van zowelansible-pylibsshalsparamiko(3.x) hebbenssh-rsahardgecodeerd uitgeschakeld, ongeacht de systeem-policy. Installeer daarom een oudere paramiko.python3 -m pip install --user 'paramiko<3.0' -
Pas je ansible.cfg aan
[defaults]host_key_checking = False[paramiko_connection]look_for_keys = Falsehost_key_auto_add = TrueDe
[paramiko_connection]sectie zorgt ervoor dat paramiko niet eerst probeert te verbinden met SSH-keys (wat faalt en de authenticatie blokkeert vóór het wachtwoord geprobeerd wordt). -
Configureer de juiste connectiemethode in je inventory
De klassieke
sshconnectiemethode van Ansible werkt niet voor network devices.
Je zal dus even moeten opzoeken welke connectiemethode er dan wel gebruikt moet worden.
Check de documentatie van Ansible...
Stap 5 - Uitvoering van rollen voor App-Deployment
Op dit moment van de opgave wordt enkel de standaard webpagina van nginx getoond.
Het kan veel interessanter worden als we een echte webapplicatie zouden kunnen gaan uitrollen die bv. ook gebruik maakt van een databank. Tegenwoordig bestaat er een overaanbod aan frameworks in verschillende programmeertalen, zowel voor front- als backend.
In deze cursus ligt de focus zeker niet op het ontwikkelen van applicaties of op de mooie weergave daarvan. Maar via IaC moet het wel mogelijk zijn om dergelijke applicaties te deployen en volledig operationeel te maken.
We kozen in deze opgave om een webapplicatie te deployen die gemaakt is met het framework Django. Django is een vrij populair en zeer veelzijdig framework dat gebaseerd is op python. Het wordt voornamelijk gebruikt als backend maar ook de layout kan in principe wel in Django zelf voor een mooi geheel zorgen. Toch wordt Django in de praktijk dikwijls gekoppeld aan echte frontend-frameworks zoals Vue, React,...
Opzet
Met Django kan je snel een webapplicatie bootstrappen die de volledige mappenstructuur voor je project aanmaakt en onmiddellijk functioneel is. Er is in principe ook een development webserver aanwezig waardoor ontwikkelaars snel het resultaat kunnen bekijken van hun applicatie. In principe zou het ook mogelijk zijn om die development server open te zetten en te laten gebruiken door de publieke wereld. Maar daar is deze interne webserver niet voor bedoeld en vooral niet performant en veilig genoeg.
python3 manage.py runserver
Een Django applicatie zal in productie typisch gebruik maken van een echte performante webserver (Nginx, Apache,...) in combinatie met python interface. Aangezien de klassieke webservers geen python "spreken", is er een extra interface nodig tussen enerzijds het Django-framework (python) en anderzijds de webserver (html). Er zijn momenteel twee interfaces die Django ondersteunt, WSGI en ASGI.
In ons project maken we gebruik van Gunicorn, wat een typische, pure Python WSGI server is.
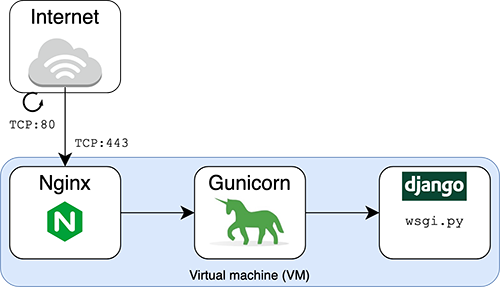
In onze situatie, waar we reeds een load balancer voorzien hebben om onze webnodes redundant te hebben, is de situatie dan als volgt:
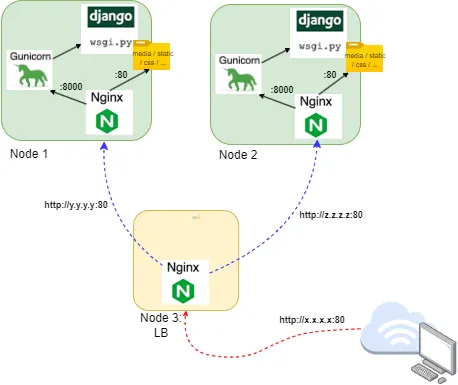
Stap 1 - Django project binnenhalen / Python Virtual Environment
Het installeren van deze volledige Django applicatie zullen we in Ansible aanpakken met een nieuwe rol: django_app.
Maak zoveel mogelijk gebruik van variabelen in de volgende rollen. Op die manier kunnen deze rollen makkelijk op andere plaatsen ingezet worden en zitten bv paden niet "ingebakken".
=> Zorg op deze manier dat het pad, waar de applicatie zal geplaatst worden, in een variabele home_folder zit.
Django project binnenhalen en rechten instellen
-
In deze eerste stap moet een voorbeeldapplicatie van gitlab, Django Applicatie, binnengehaald (gekloond) worden en in de
/var/www/iac_app/-folder geplaatst worden. -
Omdat straks de nginx-service deze bestanden moeten kunnen bereiken moeten de rechten op deze volledige folder aangepast worden. Dit kan op twee manieren. Ofwel gebruik je een ansible-module om de rechten en het ownership aan te passen naar de gebruiker
www-dataofwel voer je de vorige taak uit in naam van de gebruikerwww-dataipv de huidige gebruiker (ubuntu).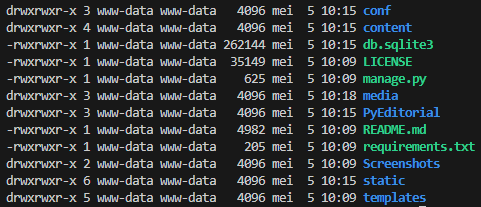
In de volgende stappen is het dikwijls van belang welke rechten je hebt op de doelhosts om commando's (modules) uit te voeren. Nu zou het makkelijk zijn om alles met sudo-rechten (become: true) uit te voeren, maar dat is geen veilige optie.
Er twee mogelijkheden om dit aan te pakken.
- Ofwel voer je volgende commando's (enkel waar dat nodig is) uit in naam van de user "www-data". Deze heeft immers voldoende rechten op de mappenstructuur, ook zonder sudo.
- Ofwel voer je de commando's uit met de huidige ansible-gebruiker (ubuntu), maar dan moet deze lid gemaakt worden van de groep "www-data" om op die manier ook voldoende rechten te krijgen in de mappenstructuur.
Deze laatste optie lijkt makkelijk te realiseren door gebruik te maken van de module "ansible.builtin.user" om de user "ubuntu" lid te maken van de groep "www-data". Er is echter een klein angeltje... Indien het gaat om de gebruiker waarmee je de ansible-connectie maakt, dan wordt dit nieuwe groepslidmaatschap niet onmiddellijk toegepast. Dat zou enkel bij een volgende "run" van je ansible-playbook toegepast worden. En dat is natuurlijk te laat als je onmiddellijk daarna deze rechten nodig hebt. Hiervoor bestaat een kleine work-around, waarmee de connectie met de doelhost heel even onderbroken wordt zodat Ansible een nieuwe connectie moet opzetten en je lidmaatschap onmiddellijk in de nieuwe shell aanwezig is.
- name: Kill SSH #https://github.com/ansible/ansible-modules-core/issues/921#issuecomment-220513111
shell: sleep 1; pkill -u {{ ansible_ssh_user }} sshd
async: 3
poll: 2
Alternatief voor bovenstaande (moderner en beter leesbaar in recente playbooks):
- name: Reset SSH connection to apply new group membership
meta: reset_connection
Python Virtual Environment installeren en starten
Een applicatie zoals Django is afhankelijk van een pak python modules. Deze moeten uiteraard allemaal geïnstalleerd worden vooraleer de applicatie kan starten. Volgens Python best practices kan elk project best in zijn eigen geïsoleerde omgeving functioneren. De geïnstalleerde packages werken dan enkel binnen deze virtual environment en kunnen geen conflicten veroorzaken met andere versies en andere applicaties.
-
installeer eerst de package in ubuntu die Python Virtual Environments kan creëren en gebruiken (python3-virtualenv)
-
Gebruik de
pipmodule in ansible om een nieuwe virtual environment, met de naam.venvte creëren (in de root van je Django app-folder) en alle nodige python modules te installeren. Alle modules die nodig zijn voor dit project staan opgelijst in het bestandrequirements.txten kan op die manier ook onmiddellijk meegegeven worden met de pip-module. -
In de volgende stap zullen we de aangemaakte virtual environment opstarten om daar enkele commando, die typisch bij ons django python-project horen, uit te voeren.
Maak gebruik van de opgegeven template die je opslaat (bv. in de .venv-map) als scriptvenv_activate.sh. Zorg dat de juiste rechten ingesteld staan zodat dit bestand uitvoerbaar is (bv mode 755). -
Als laatste stap in deze rol mag het script
venv_activate.shuitgevoerd worden. (Het is mogelijk dat je "bash" voorafgaand aan je script moet gebruiken om het script te kunnen laten uitvoeren)
In dit script worden enkele zaken die typisch met het opslaan van data (in databanken) te maken hebben, uitgevoerd.
Een eerste commando voert makemigrations uit. Dit zal op basis van de data-modellen die gemaakt werden in het project (models.py), migration-files klaarzetten. Deze beschrijven oa. hoe het databank-schema er moet uitzien en welke wijzigingen er eventueel aan de databank moeten gebeuren.
Een tweede commando, migrate, zal effectief deze wijzigingen gaan doorvoeren op de database (momenteel sqlite) en dus de nodige tabellen etc, implementeren.
Op dit moment zou je eigenlijk al de geïnstalleerde versie van het Django-project lokaal moeten kunnen testen.
Zoals eerder verteld is er een "Development server" aanwezig in het Django-framework. Deze kan je activeren door, in de virtual environment, het volgende command uit te voeren:
source {{ je folder naar het project }}/iac_app/.venv/bin/activate
python3 ./manage.py runserver 0.0.0.0:8000
Het zou dan al moeten mogelijk zijn om te surfen naar je doelhosts via het ip-adres en poort 8000. Opgelet: vergeet deze development server niet terug uit te schakelen vooraleer verder te werken.
Stap 2 - Django Database van Sqlite naar MySql / Gunicorn ipv Development-server
Op dit moment maakt ons project nog gebruik van de ingebouwde Sqlite databank en dat op elke webnode apart.
De bedoeling is dat we uiteraard gebruik gaan maken van een gemeenschappelijke database, in dit geval onze MySql-database op host 3.
In de tweede stap gaan we de development-server vervangen door een echte Python WSGI server => Gunicorn.
Voorzie onderstaande dus in een nieuwe rol met de naam django_db.
Sqllite naar MySql
-
Django zal gebruik maken van de
mysqlclientpython package om zijn connectie met MySql op te zetten.
Voorzie dus een task die de modules "mysqlclient" én "gunicorn" (straks nodig) via pip zal installeren.
Maak in de module ook zeker gebruik van je virtual environment.tipOm de mysqlclient package te kunnen installeren zijn enkele andere libraries (dependencies) nodig. Deze zal je eerst via de gewone Linux package installer moeten voorzien.
Zie https://pypi.org/project/mysqlclient/, sectie "Linux".
Nu moeten de database-connection settings aangepast worden van sqlite naar MySql. Django werd momenteel zo geconfigureerd dat de database-settings ingelezen worden via het bestand db.py in de map "PyEditorial".
- Maak gebruik van de opgegeven template om het bestaande bestand
db.pyte overschrijven met deze nieuwe settings. Volgens de best practices komen deze settings uit een vault.
Gunicorn en Migrations
Straks gaan we gunicorn uitvoeren. Deze heeft een aantal parameters nodig.
- Maak gebruik van de opgegeven template en plaats deze in een map en bestandsnaam:
conf/gunicorn_config.pyin de root van je project.
We zouden er voor kunnen kiezen om gunicorn als een systemd-service te laten draaien. Maar om de opgave niet te complex of uitgebreid te maken kiezen we voor de gewone opstart-methode, via de Python virtual environment.
Hou er rekening mee dat gunicorn in deze uitwerking dus niet automatisch herstart na een reboot. Een systemd .service-unit is daarvoor de logische volgende stap.
Nu deze settings aangepast zijn moet het volledige databank-schema nog geïmplementeerd worden in de nieuwe databank, MySql. In de "note" van stap werd reeds aangehaald hoe dit met "makemigrations" en "migrate" doorgevoerd kan worden. Aangezien er in deze situatie gebruik gemaakt zal worden van gunicorn moet ons script van daarnet een beetje gewijzigd worden.
-
Maak gebruik van de opgegeven template om een aangepast script op de doelhost te plaatsen (bv. in de .venv-map). Let opnieuw op de juiste permissies zodat het script
venv_activate_db_gunicorn.shkan uitgevoerd worden. -
Als laatste stap in deze rol mag het script
venv_activate_db_gunicorn.shuitgevoerd worden.
(Het is mogelijk dat je "bash" voorafgaand aan je script moet gebruiken om het script te kunnen laten uitvoeren)
Als controle zou je nu in principe rechtstreeks moeten kunnen connecteren met je webnodes op poort 8000. Alle sequests worden dan afgehandeld door gunicorn en ... je data zou moeten afkomstig zijn van je MySql database op host3.
Stap 3 - Nginx aanpassen
Het is niet de bedoeling dat gunicorn nu alle requests op zich neemt. Zoals eerder aangegeven kunnen bestanden die typisch statisch zijn (images, css, js, ...) beter door een gewone webserver afgehandeld worden.
In een laatste rol met de naam django_nginx passen we de configuratie aan van de nginx server zodat requests, komende van de loadbalancer vanop poort 80, opgesplitst worden.
Requests voor het URI-path /media en /static worden door nginx zelf afgehandeld. Alle andere requests worden door gunicorn afgehandeld en zullen dus door nginx, via een proxy_pass doorgestuurd worden.
- Maak gebruik van de opgegeven template om een aangepaste nginx-configuratie in te stellen.
Als alles goed verlopen is zouden requests die naar de loadbalancer gestuurd worden nu netjes naar de individuele nodes moeten doorgestuurd worden. Op hun beurt zou elke webserver nu de statische content zelf moeten afhandelen en de andere requests door gunicorn.
In de headers van de webpagina's die je opvraagt zou je ook duidelijk moeten zien van welke webserver de responses afkomstig zijn.